

Companies Unlock Innovative Value from OpenAI

With a variety of techniques available to build a custom model, organisations of all sizes can develop personalised models to realise more meaningful, specific impact from their AI implementations
Indeed, a global job matching and hiring platform, wants to simplify the hiring process. As part of this, Indeed launched a feature that sends personalised recommendations to job seekers, highlighting relevant jobs based on their skills, experience, and preferences. They fine-tuned GPT-3.5 Turbo to generate higher quality and more accurate explanations. As a result, Indeed was able to improve cost and latency by reducing the number of tokens in prompt by 80%. This let them scale from less than one million messages to job seekers per month to roughly 20 million. In the context of LLMs, tokens can be thought of as units of text that the models process and generate. They can represent individual characters, words, sub-words, or even larger linguistic units, depending on the specific tokenisation approach used. Tokens act as a bridge between the raw text data and the numerical representations that LLMs can work with.
Fine Tuning Models
Thanks to a slew of new API launches by OpenAI, companies are finding innovative ways to leverage the power of Generative AI tools. The company claims that thousands of organisations have trained hundreds of thousands of models using its API. Fine-tuning can help models deeply understand content and augment a model’s existing knowledge and capabilities for a specific task. Fine-tuning API also supports a larger volume of examples than can fit in a single prompt to achieve higher quality results while reducing cost and latency. Some of the common use cases of fine-tuning include training a model to generate better code in a particular programming language, to summarise text in a specific format, or to craft personalised content based on user behaviour.
SK Telecom using GPT4 to improve customer service
SK Telecom, a telecommunications operator serving over 30 million subscribers in South Korea, wanted to customise a model to be an expert in the telecommunications domain with an initial focus on customer service. They worked with OpenAI to fine-tune GPT-4 to improve its performance in telecom-related conversations in the Korean language. Over the course of multiple weeks, SKT and OpenAI drove meaningful performance improvement in telecom customer service tasks – a 35% increase in conversation summarisation quality, a 33% increase in intent recognition accuracy, and an increase in satisfaction scores from 3.6 to 4.5 (out of 5) when comparing the fine-tuned model to GPT-4.
ChatGPT trained for case law
Harvey, an AI-native legal tool for attorneys, partnered with OpenAI to create a custom-trained large language model for case law. While foundation models were strong at reasoning, they lacked the extensive knowledge of legal case history and other knowledge required for legal work. After testing out prompt engineering, RAG (retrieval-augmented generation), and fine-tuning, Harvey worked with the OpenAI team to add the depth of context needed to the model–the equivalent of 10 billion tokens worth of data.
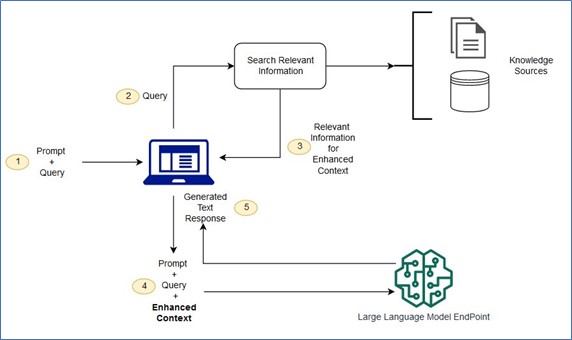
Image: Conceptual flow of using RAG with LLMs; Source: AWS
Retrieval Augmented Generation
Retrieval-Augmented Generation (RAG) is the process of optimising the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response. Large Language Models (LLMs) are trained on vast volumes of data and use billions of parameters to generate original output for tasks like answering questions, translating languages, and completing sentences. RAG extends the already powerful capabilities of LLMs to specific domains or an organisation’s internal knowledge base, all without the need to retrain the model. It is a cost-effective approach to improving LLM output, so that it remains relevant, accurate, and useful in various contexts.
The OpenAI team modified every step of the model training process, from domain-specific mid-training to customising post-training processes and incorporating expert attorney feedback. The resulting model achieved an 83% increase in factual responses and attorneys preferred the customised model’s outputs 97% of the time over GPT-4.
New Features
Early this month OpenAI has launched new features aimed at giving developers more control over their fine-tuning jobs. These include:
- Epoch-based Checkpoint Creation: This feature automatically produces a full fine-tuned model checkpoint during each training epoch. A checkpoint is a snapshot of the model’s state at a particular point in training, and creating them at each epoch can help reduce the need for subsequent retraining, especially in cases of overfitting. An epoch, in the context of machine learning and deep learning, refers to one complete pass through the entire training dataset during the training of a model. In other words, during the training process, the dataset is divided into batches, and the model sees each batch in an iteration.
- Comparative Playground: This refers to a new user interface (UI) that allows for side-by-side comparison of model quality and performance. It enables human evaluation of the outputs of multiple models or fine-tune snapshots against a single prompt.
- Third-party Integration: This feature provides support for integrating with third-party platforms, starting with Weights and Biases. This integration allows developers to share detailed fine-tuning data with other parts of their technology stack.
- Comprehensive Validation Metrics: This feature enables the computation of metrics such as loss and accuracy over the entire validation dataset, rather than just a sampled batch. This provides better insight into the quality of the model.
- Hyperparameter Configuration: This refers to the ability to configure available hyperparameters from the Dashboard, rather than only through the API (Application Programming Interface) or SDK (Software Development Kit).
- Fine-Tuning Dashboard Improvements: This includes enhancements to the fine-tuning dashboard, such as the ability to configure hyperparameters, view more detailed training metrics, and rerun jobs from previous configurations.
OpenAI is getting ready for a more engaging future when according to their forecasts a vast majority of organisations will develop customised models that are personalised to their industry, business, or use case. With a variety of techniques available to build a custom model, organisations of all sizes can develop personalised models to realise more meaningful, specific impact from their AI implementations.
Know more about the syllabus and placement record of our Top Ranked Data Science Course in Kolkata, Data Science course in Bangalore, Data Science course in Hyderabad, and Data Science course in Chennai.