

Why Every Developer Needs to Understand the Power of LLMs

The integration of Large Language Models into the software development life cycle lends a significant helping hand to developers worldwide. Yet, to fully realise their potential, they must rigorously adhere to best practices in testing, debugging and optimisation. That interplay will be critical – AI will not act as a replacement for human judgment, but as a complement.
Imagine walking into a software company a decade ago. The air is thick with tension as developers wrestle with stubborn bugs, pouring over thousands of lines of code. Whiteboards are filled with half-erased diagrams, and the constant clicking of keyboards echoes the struggle of debugging and optimisation. Fast forward to today, and a new force has entered the equation – Large Language Models (LLMs). These AI-powered assistants aren’t just changing the way we write code; they’re fundamentally altering the very process of software development, much like the financial disruptions that reshaped banking in the early 2000s.
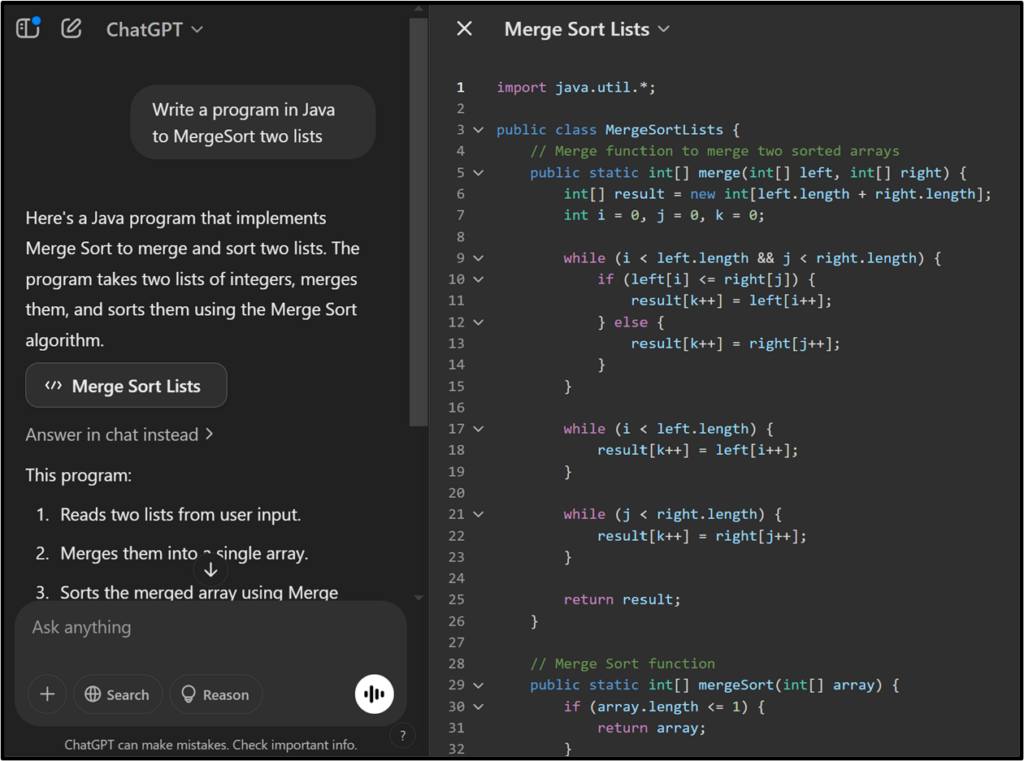
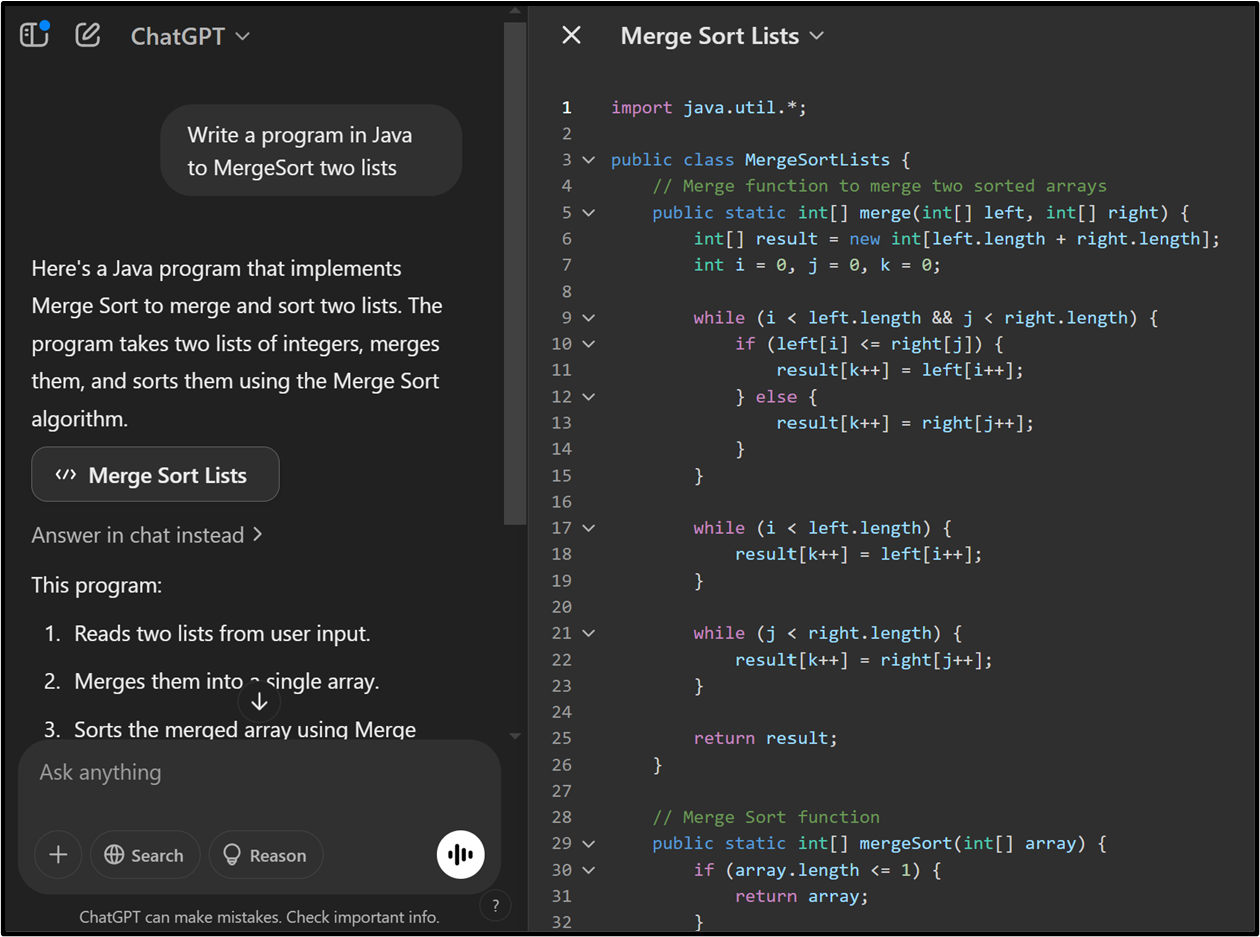
Building Robust Code with LLMs
LLMs have revolutionised code generation by transforming natural language descriptions into functional code snippets. For instance, a developer can describe a requirement, and the LLM will generate the corresponding code in the desired programming language. This capability accelerates development and ensures adherence to best practices.
However, the quality of the generated code heavily depends on the input data. Collaborating with domain experts to create diverse and representative datasets is essential. Incorporating both human-labelled and synthetic data can enhance the model’s understanding and performance. As highlighted by experts, synthetic data preserves privacy while enabling effective analysis and modelling.
Despite these benefits, LLMs are not infallible. Developers must validate generated code against business logic, security constraints, and maintainability guidelines. Best practices include integrating LLM-generated code with static analysis tools, conducting thorough peer reviews, and maintaining up-to-date documentation.
Establishing Clear Testing Protocols
Testing LLM outputs requires a structured approach. Defining specific objectives and evaluation metrics is the first step. For example, when developing an email assistant, one might assess the model’s ability to generate polite decline responses. A study revealed that an email assistant failed to produce any response 53.3% of the time when tasked with writing a polite refusal, underscoring the need for rigorous testing.
A multi-faceted testing strategy is essential. Developers should leverage unit tests, integration tests, and fuzz testing to evaluate the robustness of LLM-generated code. Regression testing helps ensure that new updates do not break existing functionality. Human-in-the-loop (HITL) evaluation remains crucial, as automated testing cannot fully capture the nuances of real-world applications.
Enhancing Debugging Practices
Debugging LLMs presents unique challenges, as these models can produce outputs that are syntactically correct but semantically flawed. Implementing a comprehensive debugging framework is essential. This includes error tracking, performance monitoring, bias detection and security testing. Tools like Langtail and Deepchecks are specifically designed for LLM debugging, offering functionalities to monitor and improve model performance.
A novel approach involves segmenting programs into basic blocks and tracking intermediate variable values during execution. This method allows for a granular examination of the code, enabling the identification and correction of errors more efficiently. Research indicates that such techniques can enhance baseline performance by up to 9.8% across various benchmarks.
Furthermore, continuous logging and observability tools are becoming indispensable. By tracking token-level responses and monitoring failure rates, teams can proactively address inconsistencies in LLM behaviour. Iterative fine-tuning based on real-world usage further refines model accuracy.
Optimising Code Execution
While LLMs do not execute code directly, they provide valuable guidance on optimising code performance. They can suggest improvements in algorithm efficiency, recommend appropriate data structures, and advise on best practices for resource management. For example, an LLM might recommend parallel processing techniques to expedite data-intensive operations.
Another key area is prompt engineering. Well-structured prompts improve the accuracy and relevance of LLM responses. Developers should experiment with different prompts, providing contextual hints and specifying constraints to achieve high-quality results. Automated prompt evaluation frameworks help streamline this process.
Monitoring tools are also essential to track the model’s performance in real-time, ensuring that resource usage is optimised, and potential bottlenecks are identified promptly. Regular updates and maintenance of the codebase, informed by LLM insights, contribute to sustained performance and scalability.
Mitigating Risks and Bias in LLM Development
Despite their potential, LLMs introduce risks such as biased outputs, hallucinations, and security vulnerabilities. Addressing these challenges requires a proactive approach:
- Bias Detection: Regular audits and adversarial testing help uncover biased responses. Models should be trained on diverse datasets to minimise biases.
- Security Considerations: LLMs should be integrated with secure coding practices to prevent unintended code execution vulnerabilities.
- Ethical Considerations: Developers must assess the ethical implications of AI-generated code, ensuring compliance with industry regulations and best practices.
Implementing explainability tools also enhances trust in LLM outputs. Techniques such as attention visualisation and token attribution analysis help developers understand model decisions and refine prompts accordingly. Further reading available here.
{kind=link}